Agentic Benchmarks#
Agentic evaluation assesses the performance of agent-based or multi-step reasoning models, especially in scenarios requiring planning, tool use, and iterative reasoning.
Key stages of agent workflow evaluation:
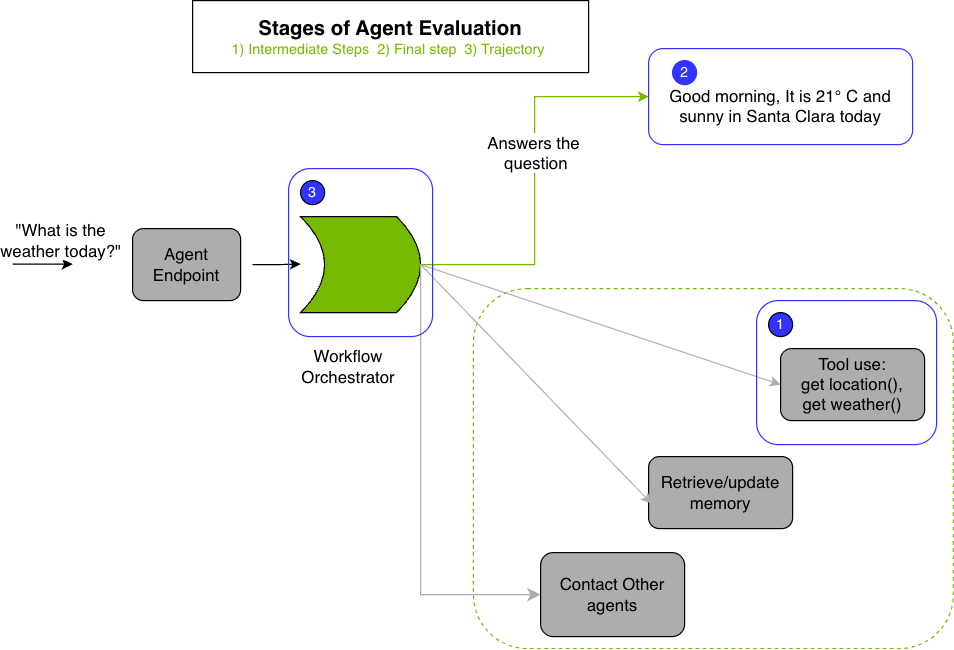
1. Intermediate Steps Evaluation Assesses the correctness of intermediate steps during agent execution:
Tool Use: Validates that the agent invoked the right tools with correct arguments at each step. See Tool Call Accuracy for implementation details.
Retriever Models: Assesses effectiveness of document retrieval pipelines using retriever metrics.
2. Final-Step Evaluation Evaluates the quality of the agent’s final output using:
Agent Goal Accuracy: Measures whether the agent successfully completed the requested task. See Agent Goal Accuracy.
Topic Adherence: Assesses how well the agent maintained focus on the assigned topic throughout the conversation. See Topic Adherence.
Custom Metrics: For domain-specific or custom evaluation criteria, use LLM-as-a-Judge with the
datatask type to evaluate agent outputs against custom metrics.
3. Trajectory Evaluation Evaluates the agent’s decision-making process by analyzing the entire sequence of actions taken to accomplish a goal. This includes assessing whether the agent chose appropriate tools in the correct order. See Trajectory Evaluation for configuration details.
Prerequisites#
Before running Agentic evaluations, ensure you have:
Workspace: Have a workspace created. All resources (metrics, secrets, jobs) are scoped to a workspace.
Dataset: Your evaluation data uploaded to a fileset:
Upload your dataset to a fileset using the Hugging Face CLI or SDK
The dataset contains generated outputs from the model in the agentic workflow
The dataset must be in JSONL format
Judge LLM (for most benchmarks): A deployed LLM to serve as the evaluation judge. Required for all benchmarks except Tool Call Accuracy. See Judge Configuration for setup details.
API key secret (if judge requires auth): If your judge endpoint requires authentication, create a secret with your API key.
For details on dataset file management, see Managing Dataset Files.
Discover Industry Benchmarks#
Discover industry benchmarks available to use for your evaluation job within the system workspace. List all industry benchmarks or filter by label category.
Note
The system workspace is a reserved workspace for NeMo Microservices that contains ready-to-use benchmarks representing industry benchmarks with published datasets and metrics.
import os
from nemo_microservices import NeMoMicroservices
client = NeMoMicroservices(base_url=os.getenv("NMP_BASE_URL"), workspace="default")
# List all agentic benchmarks within system workspace
agentic_system_benchmarks = client.evaluation.benchmarks.list(workspace="system")
for benchmark in agentic_system_benchmarks.data:
print(f"{benchmark.name}: {benchmark.description}")
Topic Adherence#
Measures topic focus in multi-turn conversations using LLM-as-a-Judge.
The benchmark can use to assess questions like “Is the agent’s answer about ‘technology’?”. Uses RAGAS metrics to score agent outputs. RAGAS is a library for evaluating retrieval-augmented generation and agentic workflows using standardized, research-backed metrics.
Topic adherence requires a judge model. Evaluation with LLM-as-a-Judge is dependent on the quality of the judge model to follow instructions for formatting a consistent and parsable output to use for metric scores.
from nemo_microservices.types.evaluation import SystemBenchmarkOfflineJobParam
job = client.evaluation.benchmark_jobs.create(
spec=SystemBenchmarkOfflineJobParam(
benchmark="system/topic-adherence",
dataset="my-workspace/agentic-dataset",
benchmark_params={
"judge": {
"model": "nvidia/llama-3.3-nemotron-super-49b-v1",
"inference_params": {
"max_tokens": 1024,
"max_retries": 10,
"request_timeout": 10
}
}
},
)
)
Judge with reasoning parameters
When using Nemotron models as the judge model, the model may require additional configuration to enable reasoning for judge evaluation.
benchmark_params = {
"judge": {
"model": "nvidia/llama-3.3-nemotron-super-49b-v1",
"system_prompt": "'detailed thinking on'",
"reasoning_params": {
"end_token": "</think>",
"include_if_not_finished": False,
}
}
}
Dataset in JSONL (JSON Lines) file format with column requirement: user_input, reference_topics
{
"user_input": [
{"content": "how to keep healthy?", "type": "human"},
{"content": "Sure. Eat more fruit", "type": "ai"}
],
"reference_topics": ["technology"]
}
Measures how well the agent sticks to the assigned topic (F1 mode)
Score name: topic_adherence(mode=f1)
Value range: 0.0–1.0
{
"tasks": {
"task1": {
"metrics": {
"topic_adherence(mode=f1)": {
"scores": {
"topic_adherence(mode=f1)": {
"value": 0.53
}
}
}
}
}
}
}
Tool Calling#
There are two system metrics available for evaluating tool calling. Both options are quality evaluations and you can choose based on your preference with the underlying library used.
Tool Calling Accuracy#
Evaluates tool/function call correctness.
The benchmark can use to assess questions like “Did the agent call the restaurant booking tool with correct args?” Uses RAGAS metrics to score agent outputs. RAGAS is a library for evaluating retrieval-augmented generation and agentic workflows using standardized, research-backed metrics.
from nemo_microservices.types.evaluation import SystemBenchmarkOfflineJobParam
job = client.evaluation.benchmark_jobs.create(
spec=SystemBenchmarkOfflineJobParam(
benchmark="system/tool-call-accuracy",
dataset="my-workspace/agentic-dataset",
benchmark_params={},
)
)
Dataset in JSONL (JSON Lines) file format with column requirement: user_input (with tool_calls), reference_tool_calls
{
"user_input": [
{"content": "What's the weather like in New York right now?", "type": "human"},
{"content": "The current temperature in New York is 75°F and it's partly cloudy.", "type": "ai", "tool_calls": [{"name": "weather_check", "args": {"location": "New York"}}]},
{"content": "Can you translate that to Celsius?", "type": "human"},
{"content": "Let me convert that to Celsius for you.", "type": "ai", "tool_calls": [{"name": "temperature_conversion", "args": {"temperature_fahrenheit": 75}}]},
{"content": "75°F is approximately 23.9°C.", "type": "tool"},
{"content": "75°F is approximately 23.9°C.", "type": "ai"}
],
"reference_tool_calls": [
{"name": "weather_check", "args": {"location": "New York"}},
{"name": "temperature_conversion", "args": {"temperature_fahrenheit": 75}}
]
}
Accuracy of tool call predictions
Score name: tool_call_accuracy
Value range: 0.0–1.0
{
"tasks": {
"task1": {
"metrics": {
"tool_call_accuracy": {
"scores": {
"tool_call_accuracy": {
"value": 1.0
}
}
}
}
}
}
}
Berkeley Function Calling Leaderboard (BFCL)#
BFCL is a benchmark for evaluating language model tool-calling capabilities. Use this evaluation type to benchmark tool-calling tasks using the Berkeley Function Calling Leaderboard.
View all available BFCL benchmarks (system/bfclv3-*) with a label filter:
bfcl_system_benchmarks = client.evaluation.benchmarks.list(
workspace="system",
extra_query={"labels": "eval_harness.bfcl"}
)
print(bfcl_system_benchmarks)
BFCL benchmark evaluation requires a model for online evaluation.
Some BFCL benchmarks call external APIs require API keys (e.g. system/bfclv3-exec-* benchmarks). Create secrets for the API keys before referencing them in the job.
RapidAPI (free tier; subscription required): Yahoo Finance, Real‑Time Amazon Data, Urban Dictionary, COVID‑19, Time Zone by Location
Direct APIs: ExchangeRate‑API, OMDb, Geocode
client.secrets.create(
workspace=workspace,
name="rapid_api_key_secret",
data="<your RapidAPI key>"
)
benchmark_params = {
"rapid_api_key": "rapid_api_key_secret",
}
from nemo_microservices.types.evaluation import SystemBenchmarkOnlineJobParam
job = client.evaluation.benchmark_jobs.create(
spec=SystemBenchmarkOnlineJobParam(
benchmark="system/bfclv3-live-simple",
model={"endpoint": "<your-nim-endpoint>/v1", "name": "nvidia/llama-3.3-nemotron-super-49b-v1"},
benchmark_params={},
)
)
Accuracy of tool call predictions
Score name: tool-calling-accuracy
Value range: 0.0–1.0
{
"tasks": {
"task1": {
"metrics": {
"tool-calling-accuracy": {
"scores": {
"tool-calling-accuracy": {
"value": 1.0
}
}
}
}
}
}
}
Agent Goal Accuracy#
Agent Goal Accuracy with Reference#
Assesses goal completion with reference using LLM-as-a-Judge.
The benchmark can use to assess questions like “Did the agent book a table as requested?”. Uses RAGAS metrics to score agent outputs. RAGAS is a library for evaluating retrieval-augmented generation and agentic workflows using standardized, research-backed metrics.
Agent goal accuracy requires a judge model. Evaluation with LLM-as-a-Judge is dependent on the quality of the judge model to follow instructions for formatting a consistent and parsable output to use for metric scores.
from nemo_microservices.types.evaluation import SystemBenchmarkOfflineJobParam
job = client.evaluation.benchmark_jobs.create(
spec=SystemBenchmarkOfflineJobParam(
benchmark="system/goal-accuracy-with-reference",
dataset="my-workspace/agentic-dataset",
benchmark_params={
"judge": {
"model": "nvidia/llama-3.3-nemotron-super-49b-v1",
"inference_params": {
"max_tokens": 1024,
"max_retries": 10,
"request_timeout": 10
}
}
},
)
)
Judge with reasoning parameters
When using Nemotron models as the judge model, the model may require additional configuration to enable reasoning for judge evaluation.
benchmark_params = {
"judge": {
"model": "nvidia/llama-3.3-nemotron-super-49b-v1",
"system_prompt": "'detailed thinking on'",
"reasoning_params": {
"end_token": "</think>",
"include_if_not_finished": False,
}
}
}
Dataset in JSONL (JSON Lines) file format with column requirement: user_input, response, reference
{
"user_input": [
{ "content": "Hey, book a table at the nearest best Chinese restaurant for 8:00pm", "type": "user" },
{ "content": "Sure, let me find the best options for you.", "type": "assistant", "tool_calls": [ { "name": "restaurant_search", "args": { "cuisine": "Chinese", "time": "8:00pm" } } ] },
{ "content": "Found a few options: 1. Golden Dragon, 2. Jade Palace", "type": "tool" },
{ "content": "I found some great options: Golden Dragon and Jade Palace. Which one would you prefer?", "type": "assistant" },
{ "content": "Let's go with Golden Dragon.", "type": "user" },
{ "content": "Great choice! I'll book a table for 8:00pm at Golden Dragon.", "type": "assistant", "tool_calls": [ { "name": "restaurant_book", "args": { "name": "Golden Dragon", "time": "8:00pm" } } ] },
{ "content": "Table booked at Golden Dragon for 8:00pm.", "type": "tool" },
{ "content": "Your table at Golden Dragon is booked for 8:00pm. Enjoy your meal!", "type": "assistant" },
{ "content": "thanks", "type": "user" }
],
"reference": "Table booked at one of the chinese restaurants at 8 pm"
}
Accuracy in achieving the agent’s goal with reference
Score name: agent_goal_accuracy
Value range: 0.0–1.0
{
"tasks": {
"task1": {
"metrics": {
"agent_goal_accuracy": {
"scores": {
"agent_goal_accuracy": {
"value": 1.0
}
}
}
}
}
}
}
Agent Goal Accuracy without Reference#
Assesses goal completion without reference using LLM-as-a-Judge.
The benchmark can use to assess questions like “Did the agent complete the requested task?”. Uses RAGAS metrics to score agent outputs. RAGAS is a library for evaluating retrieval-augmented generation and agentic workflows using standardized, research-backed metrics.
Agent goal accuracy requires a judge model. Evaluation with LLM-as-a-Judge is dependent on the quality of the judge model to follow instructions for formatting a consistent and parsable output to use for metric scores.
from nemo_microservices.types.evaluation import SystemBenchmarkOfflineJobParam
job = client.evaluation.benchmark_jobs.create(
spec=SystemBenchmarkOfflineJobParam(
benchmark="system/goal-accuracy-without-reference",
dataset="my-workspace/agentic-dataset",
benchmark_params={
"judge": {
"model": "nvidia/llama-3.3-nemotron-super-49b-v1",
"inference_params": {
"max_tokens": 1024,
"max_retries": 10,
"request_timeout": 10
}
}
},
)
)
Judge with reasoning parameters
When using Nemotron models as the judge model, the model may require additional configuration to enable reasoning for judge evaluation.
benchmark_params = {
"judge": {
"model": "nvidia/llama-3.3-nemotron-super-49b-v1",
"system_prompt": "'detailed thinking on'",
"reasoning_params": {
"end_token": "</think>",
"include_if_not_finished": False,
}
}
}
Dataset in JSONL (JSON Lines) file format with column requirement: user_input, response
{
"user_input": [
{ "content": "Set a reminder for my dentist appointment tomorrow at 2pm", "type": "user" },
{ "content": "I'll set that reminder for you.", "type": "assistant", "tool_calls": [ { "name": "set_reminder", "args": { "title": "Dentist appointment", "date": "tomorrow", "time": "2pm" } } ] },
{ "content": "Reminder set successfully.", "type": "tool" },
{ "content": "Your reminder for the dentist appointment tomorrow at 2pm has been set.", "type": "assistant" }
]
}
Accuracy in achieving the agent’s goal with reference
Score name: agent_goal_accuracy
Value range: 0.0–1.0
{
"tasks": {
"task1": {
"metrics": {
"agent_goal_accuracy": {
"scores": {
"agent_goal_accuracy": {
"value": 1.0
}
}
}
}
}
}
}
Answer Accuracy#
Checks factual correctness using LLM-as-a-Judge.
The benchmark can use to assess questions like “Did the agent answer ‘Paris’ for ‘What is the capital of France’?”. Uses RAGAS metrics to score agent outputs. RAGAS is a library for evaluating retrieval-augmented generation and agentic workflows using standardized, research-backed metrics.
Topic adherence requires a judge model. Evaluation with LLM-as-a-Judge is dependent on the quality of the judge model to follow instructions for formatting a consistent and parsable output to use for metric scores.
from nemo_microservices.types.evaluation import SystemBenchmarkOfflineJobParam
job = client.evaluation.benchmark_jobs.create(
spec=SystemBenchmarkOfflineJobParam(
benchmark="system/answer-accuracy",
dataset="my-workspace/agentic-dataset",
benchmark_params={
"judge": {
"model": "nvidia/llama-3.3-nemotron-super-49b-v1",
"inference_params": {
"max_tokens": 1024,
"max_retries": 10,
"request_timeout": 10
}
}
},
)
)
Judge with reasoning parameters
When using Nemotron models as the judge model, the model may require additional configuration to enable reasoning for judge evaluation.
benchmark_params = {
"judge": {
"model": "nvidia/llama-3.3-nemotron-super-49b-v1",
"system_prompt": "'detailed thinking on'",
"reasoning_params": {
"end_token": "</think>",
"include_if_not_finished": False,
}
}
}
Dataset in JSONL (JSON Lines) file format with column requirement: user_input, response, reference
{"user_input": "What is the capital of France?", "response": "Paris", "reference": "Paris"}
{"user_input": "Who wrote 'Pride and Prejudice'?", "response": "Jane Austen", "reference": "Jane Austen"}
Accuracy of the agent’s answer
Score name: answer_accuracy
Value range: 0.0-1.0
{
"tasks": {
"task1": {
"metrics": {
"answer_accuracy": {
"scores": {
"answer_accuracy": {
"value": 1.0
}
}
}
}
}
}
}
Trajectory Evaluation#
Trajectory evaluation assesses the agent’s decision-making process by analyzing the entire sequence of actions (trajectory) the agent took to accomplish a goal. This metric uses LangChain’s TrajectoryEvalChain to evaluate whether the agent’s choices were appropriate given the available tools and the task at hand.
Important
NAT Format Requirement: This metric supports the NVIDIA Agent Toolkit format with intermediate_steps containing detailed event traces.
Evaluates decision-making across action sequence using LLM-as-a-Judge.
The benchmark can use to assess questions like “Did the agent choose appropriate tools in the right order?”. Uses RAGAS metrics to score agent outputs. RAGAS is a library for evaluating retrieval-augmented generation and agentic workflows using standardized, research-backed metrics.
Trajectory evaluation requires a judge model. Evaluation with LLM-as-a-Judge is dependent on the quality of the judge model to follow instructions for formatting a consistent and parsable output to use for metric scores.
from nemo_microservices.types.evaluation import SystemBenchmarkOfflineJobParam
job = client.evaluation.benchmark_jobs.create(
spec=SystemBenchmarkOfflineJobParam(
benchmark="system/trajectory-evaluation",
dataset="my-workspace/agentic-dataset",
benchmark_params={
"judge": {
"model": "nvidia/llama-3.3-nemotron-super-49b-v1",
"inference_params": {
"max_tokens": 1024,
"max_retries": 10,
"request_timeout": 10
}
},
"trajectory_used_tools": "<Comma-separated list of tool names that were available to the agent during execution.>",
},
)
)
Judge with reasoning parameters
When using Nemotron models as the judge model, the model may require additional configuration to enable reasoning for judge evaluation.
benchmark_params = {
"judge": {
"model": "nvidia/llama-3.3-nemotron-super-49b-v1",
"system_prompt": "'detailed thinking on'",
"reasoning_params": {
"end_token": "</think>",
"include_if_not_finished": False,
}
}
}
Dataset in JSONL (JSON Lines) file format with column requirement: question, generated_answer, answer, intermediate_steps (NAT format)
Each data entry must follow the Nemo agent toolkit format with intermediate_steps containing event traces:
{
"question": "What are LLMs",
"generated_answer": "LLMs, or Large Language Models, are a type of artificial intelligence designed to process and generate human-like language. They are trained on vast amounts of text data and can be fine-tuned for specific tasks or guided by prompt engineering.",
"answer": "LLMs stand for Large Language Models, which are a type of machine learning model designed for natural language processing tasks such as language generation.",
"intermediate_steps": [
{
"payload": {
"event_type": "LLM_END",
"name": "nvidia/llama-3.3-nemotron-super-49b-v1",
"data": {
"input": "\nPrevious conversation history:\n\n\nQuestion: What are LLMs\n",
"output": "Thought: I need to find information about LLMs to answer this question.\n\nAction: wikipedia_search\nAction Input: {'question': 'LLMs'}\n\n"
}
}
},
{
"payload": {
"event_type": "TOOL_END",
"name": "wikipedia_search",
"data": {
"input": "{'question': 'LLMs'}",
"output": "<Document source=\"https://en.wikipedia.org/wiki/Large_language_model\" page=\"\"/>\nA large language model (LLM) is a language model trained with self-supervised machine learning..."
}
}
},
{
"payload": {
"event_type": "LLM_END",
"name": "nvidia/llama-3.3-nemotron-super-49b-v1",
"data": {
"input": "...",
"output": "Thought: I now know the final answer\n\nFinal Answer: LLMs, or Large Language Models, are a type of artificial intelligence..."
}
}
}
]
}
Evaluates the agent’s decision-making process across the entire action sequence
Score name: trajectory_evaluation
Value range: 0.0-1.0
{
"tasks": {
"task1": {
"metrics": {
"trajectory_evaluation": {
"scores": {
"trajectory_evaluation": {
"value": 0.85
}
}
}
}
}
}
}
Required Configuration Parameters#
trajectory_used_tools (string, required)
Comma-separated list of tool names that were available to the agent during execution. This helps the evaluator understand what tools the agent had at its disposal.
Example: "wikipedia_search,current_datetime,code_generation,dummy_custom_tool"
trajectory_custom_tools (object, optional)
JSON object mapping custom tool names to their descriptions. Required for any tools that are not part of the Nemo agent toolkit default functions. This helps the judge LLM understand the purpose of each custom tool.
Example:
{
"dummy_custom_tool": "Do nothing. This tool is for test only",
"code_generation": "Useful to generate Python code. For any questions about code generation, you must only use this tool!"
}
Job Management#
After successfully creating a job, navigate to Benchmark Job Management to oversee its execution, monitor progress.
See also
Agentic Evaluation Metrics - Detailed metric documentation with live and job examples
Agentic Evaluation Metrics - Detailed metric documentation with examples
Managing Secrets - Store API keys for judge endpoints
Evaluation Results - Understanding and downloading results